

Big data is a term used to describe a very large volume of data generated by the interaction of businesses, government agencies, and individuals who use the internet either through private networks or public networks. Big data also includes data from various sources such as surveys, web pages, social networks, search engines, and devices. Some successful companies use this technology to research large amounts of information and use it to their advantage.
Big data has become a trending topic in the technology world for the past five years. The media or technology companies around the world talk about big data all the time which includes the talks about crawling. However, what exactly is Web crawler? How does it work? And how important is web crawling in Big Data practices?
What is a Web crawler?
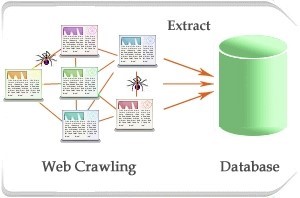
Web crawlers (also known as web spiders or web robots) is a program that works with certain methods and automatically collects all the information contained in a website. Web crawlers will visit every website address given to it, then absorb and store all the information contained in the website. Every time a web crawler visits a website, it also records all the links on the page it visits.
When crawlers find a web page, the next step is to take data from the web page and save it into a storage medium (hard disk). These stored data can later be accessed when a query is related to that data. To achieve the goal of collecting billions of web pages and presenting them in seconds, search engines need a very large and sophisticated data center to manage all this data.
The process of web crawlers visiting each web document is called web crawling or spidering. The crawling process on a website starts from listing all the URLs of the website, tracing them one by one, then entering them in the list of pages in the search engine index. Because of this step, every change on the website will be updated automatically. Web crawling is the process of taking a collection of pages from a web to be indexed and supports search engine performance. One of the site that implements web crawling is www.webcrawler.com. In addition to the site-site leading search engines of course, like Google, Yahoo, Ask, Live, and so forth.
Web crawlers are used to make copies of part or all of the web pages that have been visited to be further processed by the index compiler system. Crawlers can also be used for the process of maintaining a website, such as validating the HTML code of a website, crawlers also used to obtain special data such as collecting e-mail addresses.
Web crawlers are included in the category of software agents or better known as bot programs. In general, crawlers begin the process by listing a number of website addresses to visit, called seeds. Every time a web page is visited, the crawler will look for other addresses contained in it and add to the list of seeds before.
Big companies have used Big Data to identify opportunities, increase customer experience and maximize profits. For example, look at what Google is doing. Google has collected a large amount of data by crawling billions of web pages from around the world. Google then uses a large amount of this data and combined with other data collected from search engine queries, they succeed in increasing the effectiveness of Google Adwords and also improve the search experience of their users at the same time. By continuing to do that, Google has generated more profit for the company and also their Adwords customers, on the other hand, it keeps the users satisfied.
Likewise, Facebook and Linkedin, which have managed to take advantage of a large amount of information they have collected also provided more effective advertising than before. They have so much data about their users that advertising targets and product recommendations are more accurate. Big data can also be used to present data visually. Things like data visualization will make users or customers more attached to the product to make the company’s products more successful.
To build a large scale data-based business requires a lot of time, energy, and funds. Even with just founding a startup with a small data-based product is not easy. One of the main reasons why building data-based products are very difficult is because of the large amount of data that companies must collect before launching their products. The majority of the data collected was obtained from the following sources:
- Direct input from customers, through surveys and questionnaires.
- Using third party APIs like Facebook API, Twitter API and so on.
- Web Server logs such as Apache and Nginx
- Web crawling or Web Scraping
From these sources, most data-based companies crawl web pages to collect data because the majority of data that companies need is in the form of web pages without API access. However, crawling web pages is not easy.
The internet is a sea of information with billions of web pages created every day. Most of the data contained in web pages is unstructured and messy. Collecting and organizing these data is not easy. When making data-based products, almost 90% of the time is spent collecting, cleaning, and filtering data. And, when it comes to crawling web pages, companies must have good programming and database skills. There is no data on the web page that is given easily. Sometimes, extracting web pages becomes more difficult when data that has to be scraped comes from difficult sources such as PDF files. However, extracting data from these sources is needed in order to be able to harvest profits for the company’s business.
Many companies in this decade employ skilled programmers and data scientists for web crawling and data analytics that cost a lot of money. In fact, with the advent of Big Data and its web crawlers, spending time and money on crawling web pages is no longer effective.
From today onwards, we will continue to hear a lot of news about Big Data and data-based startup companies. Companies with better Big Data knowledge will be able to provide a better experience for their customers, find potential customers, and generate more profits.
Web crawling is an important part of most data-based product development, which of course requires a lot of time, effort, and funds. However, by choosing the right Big Data appliance like Paques, the company will be able to save a lot of time and money.
Sumber: grepsr.com & teknologi-bigdata
